大模型数据分析之NPL2AnyLine2SQL
NLP2SQL技术的方言兼容性是影响其跨数据库系统落地效果的关键因素。
一、SQL方言差异的根源与影响
不同数据库系统对SQL标准的扩展差异显著,例如:
-
语法结构差异:Oracle的
ROWNUM伪列、MySQL的LIMIT子句、SQL Server的TOP语法在分页查询中互不兼容,需针对性适配。 -
函数支持差异:日期处理函数如
DATE_ADD(MySQL)、DATEADD(SQL Server)存在参数格式差异,影响时间条件生成。 -
数据类型映射:Oracle的
VARCHAR2与MySQL的VARCHAR在精度定义和存储行为上存在细微差异,需在Schema理解阶段处理。
二、技术实现中的方言兼容策略
主流NLP2SQL框架通过以下技术路径实现兼容:
-
抽象语法层设计:
采用AST(抽象语法树)中间表示,将自然语言解析为数据库无关的逻辑查询计划,再通过方言转换器生成目标SQL。
例如:Apache Calcite通过RelNode构建逻辑执行计划,支持PostgreSQL、Hive等方言映射。 -
方言感知生成器:
基于Transformer的模型(如T5、GPT)通过多任务学习融合方言特征,在微调阶段加入方言标签(如--dialect mysql)引导生成。
实验表明,方言感知微调可使跨方言准确率提升15%-20%。 -
动态SQL改写引擎:
规则引擎(如Apache Druid的SQL方言适配层)通过模式匹配替换方言特定语法,例如将SELECT TOP 10改写为LIMIT 10。
结合AST验证确保改写后的SQL语义一致。"
AnyLine如何解决方言兼容问题
AnyLine采用的第1种方式抽象语法层设计,这种方式的工作量最大,需要为每个数据库定制适配器生成特定的SQL,但可以保证准确性,而不是像大模型一样靠概率。而实际工作量也不是非常大,因为数据库的类型是有限的,通过层层继承,最后需要实现的方法并没有多少个,只需要实现差异部分即可。参考一下传统项目中【AnyLine数据读取的过程】。
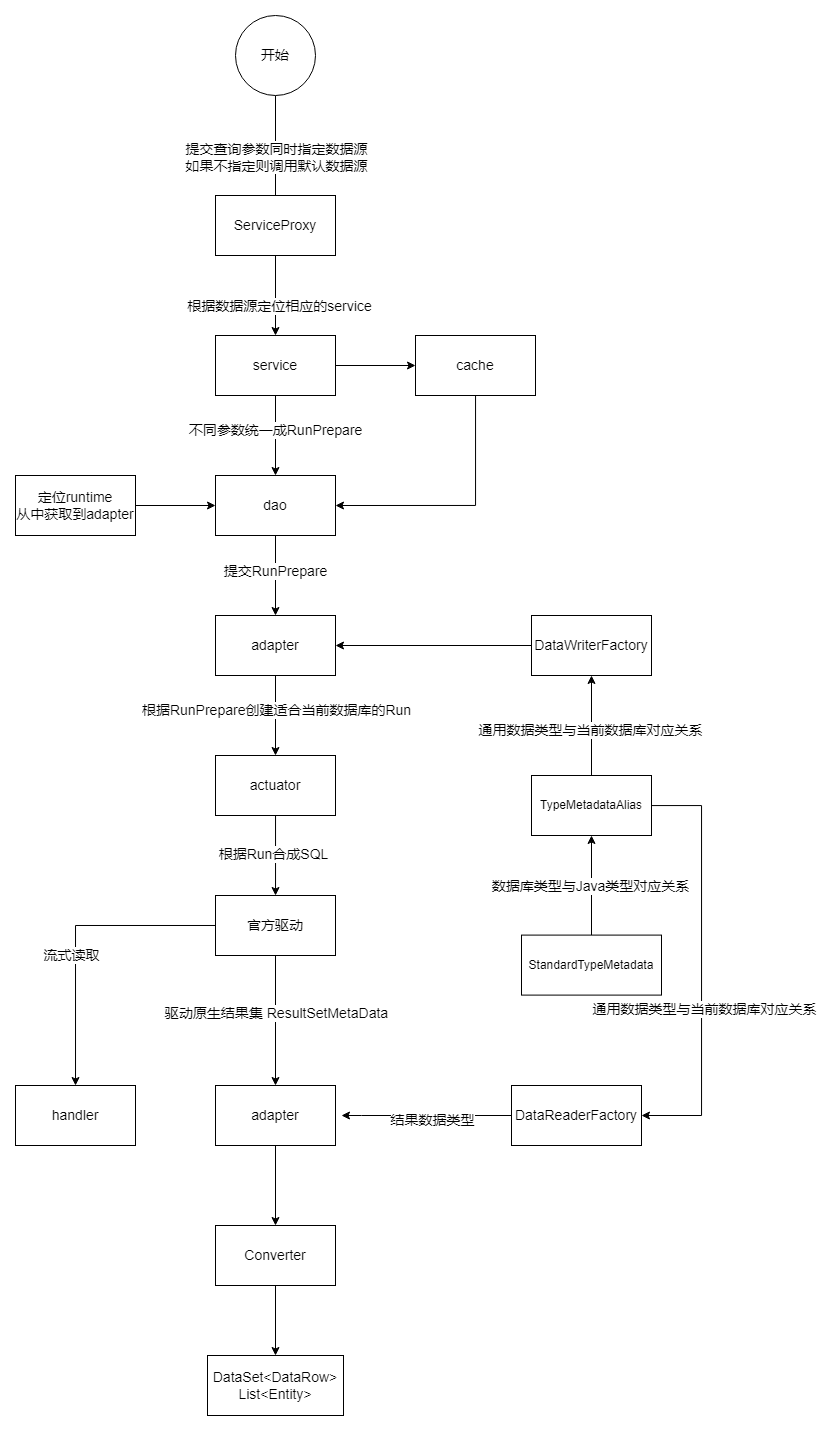
方言兼容发生在adapter环节,目前已经适配了100+的关系型及非关系型数据库,作到不同数据库操作的一致性。
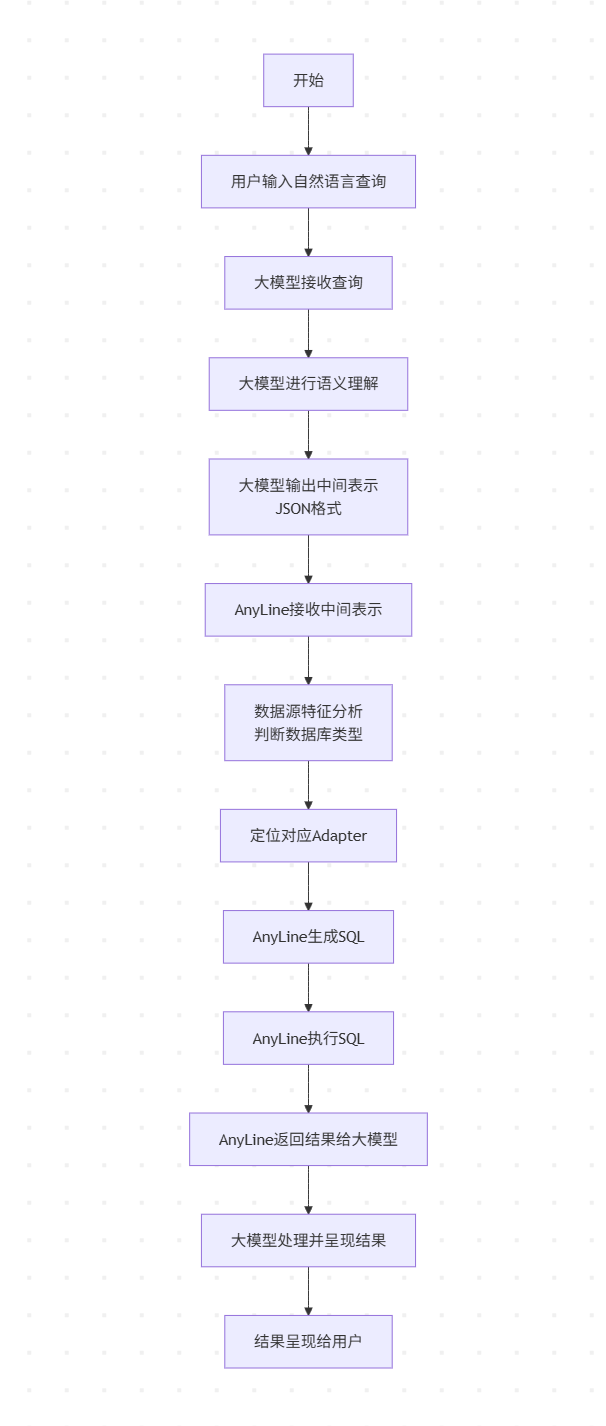
AnyLine在大模型数据分析NLP2SQL环节实现“语义理解”与“数据库执行”解耦,最终实现NLP2AnyLine2SQL
AnyLine与大模型协同实现NLP2SQL解耦的完整工作流程:
1. 元数据理解阶段
大模型首先调用AnyLine获取数据库元数据(表结构、字段类型、关系约束等),建立对目标数据库的基础认知框架。这一步骤确保后续语义理解不会产生结构性错误。
2. 语义解析阶段
大模型接收用户自然语言查询后:
- 识别核心操作类型(查询/聚合/排序等)
- 提取关键实体(时间范围、筛选字段等)
- 构建条件逻辑树(AND/OR嵌套关系)
-
输出符合AnyLine约定的JSON中间表示,约定有两类:
1.多表关联关系约定
2.查询条件约定
3. 执行反馈阶段
AnyLine接收到中间表示后:
- 进行SQL方言适配(MySQL/Oracle等)
- 自动优化查询计划(索引提示、子查询处理)
- 执行后返回结构化数据结果
- 大模型对原始数据做最终呈现处理(单位换算、趋势分析等)
最张实现使大模型无需感知数据库物理细节,AnyLine则专注查询优化与执行,双方通过标准化JSON接口实现高效协作。
mermaid 流程图
graph TD
A[开始] --> B[用户输入自然语言查询]
B --> C[大模型接收查询]
C --> D[大模型进行语义理解]
D --> E[大模型输出中间表示JSON格式]
E --> F[AnyLine接收中间表示]
F --> G[AnyLine生成SQL]
G --> H[AnyLine执行SQL]
H --> I[AnyLine返回结果给大模型]
I --> J[大模型处理并呈现结果]
J --> K[结果呈现给用户]